| Age | Commit message (Collapse) | Author | Files | Lines |
|---|
|
Originally added for reproducers, it is now only used for test code.
While we could make it a test helper, I think that after #145015 it is
simple enough to not be needed.
Also squeeze in a change to make ConnectionFileDescriptor accept a
unique_ptr<Socket>.
|
|
This is intended for use with Arm's Guarded Control Stack extension
(GCS). Which reuses some existing shadow stack support in Linux. It
should also work with the x86 equivalent.
A "ss" flag is added to the "VmFlags" line of shadow stack memory
regions in `/proc/<pid>/smaps`. To keep the naming generic I've called
it shadow stack instead of guarded control stack.
Also the wording is "shadow stack: yes" because the shadow stack region
is just where it's stored. It's enabled for the whole process or it
isn't. As opposed to memory tagging which can be enabled per region, so
"memory tagging: enabled" fits better for that.
I've added a test case that is also intended to be the start of a set of
tests for GCS. This should help me avoid duplicating the inline assembly
needed.
Note that no special compiler support is needed for the test. However,
for the intial enabling of GCS (assuming the libc isn't doing it) we do
need to use an inline assembly version of prctl.
This is because as soon as you enable GCS, all returns are checked
against the GCS. If the GCS is empty, the program will fault. In other
words, you can never return from the function that enabled GCS, unless
you push values onto it (which is possible but not needed here).
So you cannot use the libc's prctl wrapper for this reason. You can use
that wrapper for anything else, as we do to check if GCS is enabled.
|
|
This should cause the memory region info "is stack" field to be set to
"no".
|
|
The existing algorithm was performing the following comparisons for an
`aaa,bbb,ccc,ddd`:
aaa\0bbb,ccc,ddd == "stack"
aaa\0bbb\0ccc,ddd == "stack"
aaa\0bbb\0ccc\0ddd == "stack"
Which wouldn't work. This commit just dispatches to a known algorithm
implementation.
|
|
In older versions there is this problem:
https://developercommunity.visualstudio.com/t/c-shared-state-futuresstate-default-constructs-the/60897
Which prevents us making a future out of a result type. There's
no good workaround so just don't compile this for older versions.
|
|
This is a retake of https://github.com/llvm/llvm-project/pull/90921
which got reverted because I forgot to modify the CalculateMD5 unit test
I had added in https://github.com/llvm/llvm-project/pull/88812
The prior failing build is here:
https://lab.llvm.org/buildbot/#/builders/68/builds/73622
To make sure this error doesn't happen, I ran `ninja
ProcessGdbRemoteTests` and then executed the resulting test binary and
observed the `CalculateMD5` test passed.
# Overview
In my previous PR: https://github.com/llvm/llvm-project/pull/88812,
@JDevlieghere suggested to match return types of the various calculate
md5 functions.
This PR achieves that by changing the various calculate md5 functions to
return `llvm::ErrorOr<llvm::MD5::MD5Result>`.
The suggestion was to go for `std::optional<>` but I opted for
`llvm::ErrorOr<>` because local calculate md5 was already possibly
returning `ErrorOr`.
To make sure I didn't break the md5 calculation functionality, I ran
some tests for the gdb remote client, and things seem to work.
# Testing
1. Remote file doesn't exist
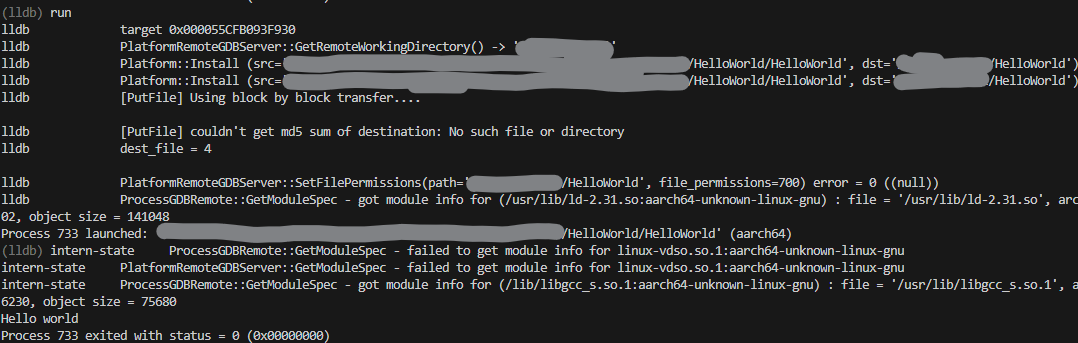
1. Remote file differs
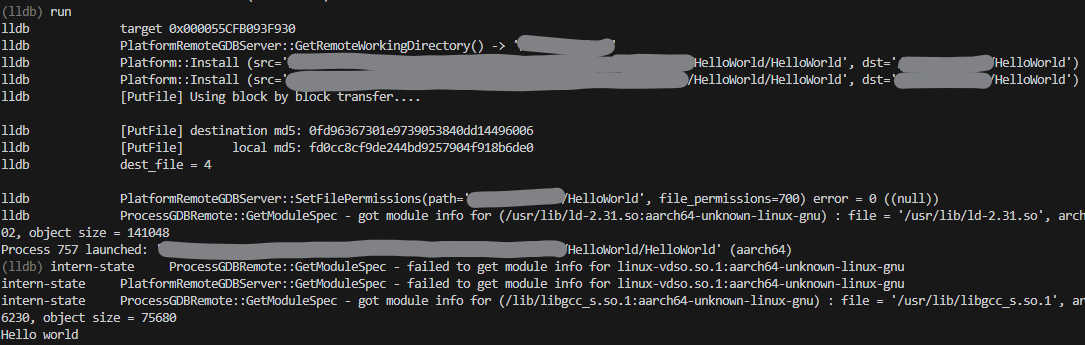
1. Remote file matches
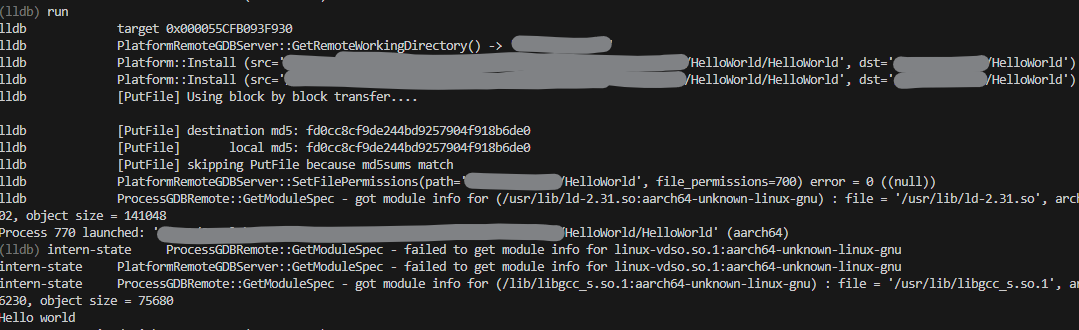
## Test gaps
Unfortunately, I had to modify
`lldb/source/Plugins/Platform/MacOSX/PlatformDarwinDevice.cpp` and I
can't test the changes there. Hopefully, the existing test suite / code
review from whomever is reading this will catch any issues.
|
|
This PR adds a check within `PutFile` to exit early when both local and
destination files have matching MD5 hashes. If they differ, or there is
trouble getting the hashes, the regular code path to put the file is
run.
As I needed this to talk to an `lldb-server` which runs the gdb-remote
protocol, I enabled `CalculateMD5` within `Platform/gdb-server` and also
found and fixed a parsing bug within it as well. Before this PR, the
client is incorrectly parsing the response packet containing the
checksum; after this PR, hopefully this is fixed. There is a test for
the parsing behavior included in this PR.
---------
Co-authored-by: Anthony Ha <antha@microsoft.com>
|
|
/data/llvm-project/third-party/unittest/googletest/include/gtest/gtest.h:1526:11: error: comparison of integers of different signs: 'const int' and 'const unsigned long' [-Werror,-Wsign-compare]
if (lhs == rhs) {
~~~ ^ ~~~
/data/llvm-project/third-party/unittest/googletest/include/gtest/gtest.h:1553:12: note: in instantiation of function template specialization 'testing::internal::CmpHelperEQ<int, unsigned long>' requested here
return CmpHelperEQ(lhs_expression, rhs_expression, lhs, rhs);
^
/data/llvm-project/lldb/unittests/Process/gdb-remote/GDBRemoteCommunicationClientTest.cpp:303:3: note: in instantiation of function template specialization 'testing::internal::EqHelper::Compare<int, unsigned long, nullptr>' requested here
ASSERT_EQ(10, num_packets);
^
/data/llvm-project/third-party/unittest/googletest/include/gtest/gtest.h:2056:32: note: expanded from macro 'ASSERT_EQ'
^
/data/llvm-project/third-party/unittest/googletest/include/gtest/gtest.h:2040:54: note: expanded from macro 'GTEST_ASSERT_EQ'
ASSERT_PRED_FORMAT2(::testing::internal::EqHelper::Compare, val1, val2)
^
1 error generated.
|
|
This patch refactors the `StructuredData::Integer` class to make it
templated, makes it private and adds 2 public specialization for both
`int64_t` & `uint64_t` with a public type aliases, respectively
`SignedInteger` & `UnsignedInteger`.
It adds new getter for signed and unsigned interger values to the
`StructuredData::Object` base class and changes the implementation of
`StructuredData::Array::GetItemAtIndexAsInteger` and
`StructuredData::Dictionary::GetValueForKeyAsInteger` to support signed
and unsigned integers.
This patch also adds 2 new `Get{Signed,Unsigned}IntegerValue` to the
`SBStructuredData` class and marks `GetIntegerValue` as deprecated.
Finally, this patch audits all the caller of `StructuredData::Integer`
or `StructuredData::GetIntegerValue` to use the proper type as well the
various tests that uses `SBStructuredData.GetIntegerValue`.
rdar://105575764
Differential Revision: https://reviews.llvm.org/D150485
Signed-off-by: Med Ismail Bennani <ismail@bennani.ma>
|
|
Instead of taking a `const std::string &` we can take an
`llvm::StringRef`. The motivation for this change is that many of the
callers of `ParseJSON` end up creating a temporary `std::string` from an existing
`StringRef` or `const char *` in order to satisfy the API. There's no
reason we need to do this.
Differential Revision: https://reviews.llvm.org/D148579
|
|
This patch replaces (llvm::|)Optional< with std::optional<. I'll post
a separate patch to clean up the "using" declarations, #include
"llvm/ADT/Optional.h", etc.
This is part of an effort to migrate from llvm::Optional to
std::optional:
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
|
|
This patch adds #include <optional> to those files containing
llvm::Optional<...> or Optional<...>.
I'll post a separate patch to actually replace llvm::Optional with
std::optional.
This is part of an effort to migrate from llvm::Optional to
std::optional:
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
|
|
std::optional::value() has undesired exception checking semantics and is
unavailable in some older Xcode. The call sites block std::optional migration.
|
|
This patch mechanically replaces None with std::nullopt where the
compiler would warn if None were deprecated. The intent is to reduce
the amount of manual work required in migrating from Optional to
std::optional.
This is part of an effort to migrate from llvm::Optional to
std::optional:
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
|
|
Previously, depending on how you constructed a UUID from data or a
StringRef, an input value of all zeros was valid (e.g. setFromData)
or not (e.g. setFromOptionalData). Since there was no way to tell
which interpretation to use, it was done somewhat inconsistently.
This standardizes the meaning of a UUID of all zeros to Not Valid,
and removes all the Optional methods and their uses, as well as the
static factories that supported them.
Differential Revision: https://reviews.llvm.org/D132191
|
|
|
|
|
|
This reverts commit aa8feeefd3ac6c78ee8f67bf033976fc7d68bc6d.
|
|
|
|
The type field is a signed integer.
(https://sourceware.org/gdb/current/onlinedocs/gdb/General-Query-Packets.html)
However it's not packed in the packet in the way
you might think. For example the type -1 should be:
qMemTags:<addr>,<len>:ffffffff
Instead of:
qMemTags:<addr>,<len>:-1
This change makes lldb-server's parsing more strict
and adds more tests to check that we handle negative types
correctly in lldb and lldb-server.
We only support one tag type value at this point,
for AArch64 MTE, which is positive. So this doesn't change
any of those interactions. It just brings us in line with GDB.
Also check that the test target has MTE. Previously
we just checked that we were AArch64 with a toolchain
that supports MTE.
Finally, update the tag type check for QMemTags to use
the same conversion steps that qMemTags now does.
Using static_cast can invoke UB and though we do do a limit
check to avoid this, I think it's clearer with the new method.
Reviewed By: omjavaid
Differential Revision: https://reviews.llvm.org/D104914
|
|
This adds memory tag writing to Process and the
GDB remote code. Supporting work for the
"memory tag write" command. (to follow)
Process WriteMemoryTags is similair to ReadMemoryTags.
It will pack the tags then call DoWriteMemoryTags.
That function will send the QMemTags packet to the gdb-remote.
The QMemTags packet follows the GDB specification in:
https://sourceware.org/gdb/current/onlinedocs/gdb/General-Query-Packets.html#General-Query-Packets
Note that lldb-server will be treating partial writes as
complete failures. So lldb doesn't need to handle the partial
write case in any special way.
Reviewed By: omjavaid
Differential Revision: https://reviews.llvm.org/D105181
|
|
Change SetCurrentThread*() logic not to include the zero padding
in PID/TID that was a side effect of 02ef0f5ab483. This should fix
problems caused by sending 64-bit integers to 32-bit servers. Reported
by Ted Woodward.
Differential Revision: https://reviews.llvm.org/D106832
|
|
This reverts commit 82a38837150099288a1262391ef43e1fd69ffde4.
The original version had a copy-paste error: using the Interrupt timeout
for the ResumeSynchronous wait, which is clearly wrong. This error would
have been evident with real use, but the interrupt is long enough that it
only caused one testsuite failure (in the Swift fork).
Anyway, I found that mistake and fixed it and checked all the other places
where I had to plumb through a timeout, and added a test with a short
interrupt timeout stepping over a function that takes 3x the interrupt timeout
to complete, so that should detect a similar mistake in the future.
|
|
Refactor SetCurrentThread() and SetCurrentThreadForRun() to reduce code
duplication and simplify it. Both methods now call common
SendSetCurrentThreadPacket() that implements the common protocol
exchange part (the only variable is sending `Hg` vs `Hc`) and returns
the selected TID. The logic is rewritten to use a StreamString
instead of snprintf().
A side effect of the change is that thread-id sent is now zero-padded.
However, this should not have practical impact on the server as both
forms are equivalent.
Differential Revision: https://reviews.llvm.org/D100459
|
|
These were disabled in 473a3a773ea565612e836ae6c2093178c5a9eb72
because they failed on 32 bit platforms. (Arm for sure but I assume
any 32 bit)
This was due to the printf formatter used. These assumed
that types like uint64_t/size_t would be certain size/type and
that changes on 32 bit.
Instead use "z" to print the size_t and PRI<...> formatters
for the addr_t (always uint64_t) and the int32_t.
|
|
check_qmemtags tests are broken on Arm 32 bits. This patch disables
these tests.
Differential Revision: https://reviews.llvm.org/D95602
|
|
This adds GDB client support for the qMemTags packet
which reads memory tags. Following the design
which was recently committed to GDB.
https://sourceware.org/gdb/current/onlinedocs/gdb/General-Query-Packets.html#General-Query-Packets
(look for qMemTags)
lldb commands will use the new Process methods
GetMemoryTagManager and ReadMemoryTags.
The former takes a range and checks that:
* The current process architecture has an architecture plugin
* That plugin provides a MemoryTagManager
* That the range of memory requested lies in a tagged range
(it will expand it to granules for you)
If all that was true you get a MemoryTagManager you
can give to ReadMemoryTags.
This two step process is done to allow commands to get the
tag manager without having to read tags as well. For example
you might just want to remove a logical tag, or error early
if a range with tagged addresses is inverted.
Note that getting a MemoryTagManager doesn't mean that the process
or a specific memory range is tagged. Those are seperate checks.
Having a tag manager just means this architecture *could* have
a tagging feature enabled.
An architecture plugin has been added for AArch64 which
will return a MemoryTagManagerAArch64MTE, which was added in a
previous patch.
Reviewed By: omjavaid
Differential Revision: https://reviews.llvm.org/D95602
|
|
This adds a basic SB API for creating and stopping traces.
Note: This doesn't add any APIs for inspecting individual instructions. That'd be a more complicated change and it might be better to enhande the dump functionality to output the data in binary format. I'll leave that for a later diff.
This also enhances the existing tests so that they test the same flow using both the command interface and the SB API.
I also did some cleanup of legacy code.
Differential Revision: https://reviews.llvm.org/D103500
|
|
This reverts commit bd5751f3d249ec0798060bd98c07272174c52af0.
This patch series is causing us to every so often miss switching
the state from eStateRunning to eStateStopped when we get the stop
packet from the debug server.
Reverting till I can figure out how that could be happening.
|
|
ProcessGDBRemote plugin layers.
Also fix a bug where if we tried to interrupt, but the ReadPacket
wakeup timer woke us up just after the timeout, we would break out
the switch, but then since we immediately check if the response is
empty & fail if it is, we could end up actually only giving a
small interval to the interrupt.
Differential Revision: https://reviews.llvm.org/D102085
|
|
Errors found in
https://lab.llvm.org/buildbot/#/builders/68/builds/9681/steps/6/logs/stdio
|
|
This implements the interactive trace start and stop methods.
This diff ended up being much larger than I anticipated because, by doing it, I found that I had implemented in the beginning many things in a non optimal way. In any case, the code is much better now.
There's a lot of boilerplate code due to the gdb-remote protocol, but the main changes are:
- New tracing packets: jLLDBTraceStop, jLLDBTraceStart, jLLDBTraceGetBinaryData. The gdb-remote packet definitions are quite comprehensive.
- Implementation of the "process trace start|stop" and "thread trace start|stop" commands.
- Implementaiton of an API in Trace.h to interact with live traces.
- Created an IntelPTDecoder for live threads, that use the debugger's stop id as checkpoint for its internal cache.
- Added a functionality to stop the process in case "process tracing" is enabled and a new thread can't traced.
- Added tests
I have some ideas to unify the code paths for post mortem and live threads, but I'll do that in another diff.
Differential Revision: https://reviews.llvm.org/D91679
|
|
This extends the "memory region" command to
show tagged regions on AArch64 Linux when the MTE
extension is enabled.
(lldb) memory region the_page
[0x0000fffff7ff8000-0x0000fffff7ff9000) rw-
memory tagging: enabled
This is done by adding an optional "flags" field to
the qMemoryRegion packet. The only supported flag is
"mt" but this can be extended.
This "mt" flag is read from /proc/{pid}/smaps on Linux,
other platforms will leave out the "flags" field.
Where this "mt" flag is received "memory region" will
show that it is enabled. If it is not or the target
doesn't support memory tagging, the line is not shown.
(since majority of the time tagging will not be enabled)
Testing is added for the existing /proc/{pid}/maps
parsing and the new smaps parsing.
Minidump parsing has been updated where needed,
though it only uses maps not smaps.
Target specific tests can be run with QEMU and I have
added MTE flags to the existing helper scripts.
Reviewed By: labath
Differential Revision: https://reviews.llvm.org/D87442
|
|
Buildbot failed on Windows
http://lab.llvm.org:8011/#/builders/83/builds/693
Error: On Windows, std::future can't hold an Expected, as it doesn't have a default
constructor.
Solution: Use std::future<bool> instead of std::future<Expected<T>>
|
|
Depends on D89283.
The goal of this packet (jTraceGetSupportedType) is to be able to query the gdb-server for the tracing technology that can work for the current debuggeer, which can make the user experience simpler but allowing the user to simply type
thread trace start
to start tracing the current thread without even telling the debugger to use "intel-pt", for example. Similarly, `thread trace start [args...]` would accept args beloging to the working trace type.
Also, if the user typed
help thread trace start
We could directly show the help information of the trace type that is supported for the target, or mention instead that no tracing is supported, if that's the case.
I added some simple tests, besides, when I ran this on my machine with intel-pt support, I got
$ process plugin packet send "jTraceSupportedType"
packet: jTraceSupportedType
response: {"description":"Intel Processor Trace","pluginName":"intel-pt"}
On a machine without intel-pt support, I got
$ process plugin packet send "jTraceSupportedType"
packet: jTraceSupportedType
response: E00;
Reviewed By: clayborg, labath
Differential Revision: https://reviews.llvm.org/D90490
|
|
Summary:
This packet is necessary to make lldb work with the remote-gdb stub in
user mode qemu when running position-independent binaries. It reports
the relative position (load bias) of the loaded executable wrt. the
addresses in the file itself.
Lldb needs to know this information in order to correctly set the load
address of the executable. Normally, lldb would be able to find this out
on its own by following the breadcrumbs in the process auxiliary vector,
but we can't do this here because qemu does not support the
qXfer:auxv:read packet.
This patch does not implement full scope of the qOffsets packet (it only
supports packets with identical code, data and bss offsets), because it
is not fully clear how should the different offsets be handled and I am
not aware of a producer which would make use of this feature (qemu will
always
<https://github.com/qemu/qemu/blob/master/linux-user/elfload.c#L2436>
return the same value for code and data offsets). In fact, even gdb
ignores the offset for the bss sections, and uses the "data" offset
instead. So, until the we need more of this packet, I think it's best
to stick to the simplest solution possible. This patch simply rejects
replies with non-uniform offsets.
Reviewers: clayborg, jasonmolenda
Subscribers: lldb-commits
Tags: #lldb
Differential Revision: https://reviews.llvm.org/D74598
|
|
This has the same behavior as converting std::string_view to
std::string. This is an expensive conversion, so explicit conversions
are helpful for avoiding unneccessary string copies.
|
|
This is how it should've been and brings it more in line with
std::string_view. There should be no functional change here.
This is mostly mechanical from a custom clang-tidy check, with a lot of
manual fixups. It uncovers a lot of minor inefficiencies.
This doesn't actually modify StringRef yet, I'll do that in a follow-up.
|
|
Summary:
A *.cpp file header in LLDB (and in LLDB) should like this:
```
//===-- TestUtilities.cpp -------------------------------------------------===//
```
However in LLDB most of our source files have arbitrary changes to this format and
these changes are spreading through LLDB as folks usually just use the existing
source files as templates for their new files (most notably the unnecessary
editor language indicator `-*- C++ -*-` is spreading and in every review
someone is pointing out that this is wrong, resulting in people pointing out that this
is done in the same way in other files).
This patch removes most of these inconsistencies including the editor language indicators,
all the different missing/additional '-' characters, files that center the file name, missing
trailing `===//` (mostly caused by clang-format breaking the line).
Reviewers: aprantl, espindola, jfb, shafik, JDevlieghere
Reviewed By: JDevlieghere
Subscribers: dexonsmith, wuzish, emaste, sdardis, nemanjai, kbarton, MaskRay, atanasyan, arphaman, jfb, abidh, jsji, JDevlieghere, usaxena95, lldb-commits
Tags: #lldb
Differential Revision: https://reviews.llvm.org/D73258
|
|
This patch replaces the hand-rolled JSON emission in StructuredData with
LLVM's JSON library.
Differential revision: https://reviews.llvm.org/D68248
llvm-svn: 373359
|
|
to reflect the new license.
We understand that people may be surprised that we're moving the header
entirely to discuss the new license. We checked this carefully with the
Foundation's lawyer and we believe this is the correct approach.
Essentially, all code in the project is now made available by the LLVM
project under our new license, so you will see that the license headers
include that license only. Some of our contributors have contributed
code under our old license, and accordingly, we have retained a copy of
our old license notice in the top-level files in each project and
repository.
llvm-svn: 351636
|
|
llvm-svn: 346780
|
|
This patch removes the logic for resolving paths out of FileSpec and
updates call sites to rely on the FileSystem class instead.
Differential revision: https://reviews.llvm.org/D53915
llvm-svn: 345890
|
|
Summary:
During the previous attempt to generalize the UUID class, it was
suggested that we represent invalid UUIDs as length zero (previously, we
used an all-zero UUID for that). This meant that some valid build-ids
could not be represented (it's possible however unlikely that a checksum of
some file would be zero) and complicated adding support for variable
length build-ids (should a 16-byte empty UUID compare equal to a 20-byte
empty UUID?).
This patch resolves these issues by introducing a canonical
representation for an invalid UUID. The slight complication here is that
some clients (MachO) actually use the all-zero notation to mean "no UUID
has been set". To keep this use case working (while making it very
explicit about which construction semantices are wanted), replaced the
UUID constructors and the SetBytes functions with named factory methods.
- "fromData" creates a UUID from the given data, and it treats all bytes
equally.
- "fromOptionalData" first checks the data contents - if all bytes are
zero, it treats this as an invalid/empty UUID.
Reviewers: clayborg, sas, lemo, davide, espindola
Subscribers: emaste, lldb-commits, arichardson
Differential Revision: https://reviews.llvm.org/D48479
llvm-svn: 335612
|
|
Summary:
The llvm version of the enum has the same enumerators, with stlightly
different names, so this is mostly just a search&replace exercise. One
concrete benefit of this is that we can remove the function for
converting between the two enums.
To avoid typing llvm::sys::path::Style::windows everywhere I import the
enum into the FileSpec class, so it can be referenced as
FileSpec::Style::windows.
Reviewers: zturner, clayborg
Subscribers: lldb-commits
Differential Revision: https://reviews.llvm.org/D46753
llvm-svn: 332247
|
|
In case we are building with xml enabled, the GetMemoryRegionInfo
function will send extra packets to query te extended memory map, which
the tests were not expecting.
Add an expectation for this to the test. Right now, it's just a basic
one which pretends we don't support the extension, however, it would be
also interesting the add a test which verifies the extension-enabled
case.
I also noticed that the test does a pretty lousy job of validating the
returned memory region info, so I add a couple of extra assertions to
improve that.
llvm-svn: 331374
|
|
The recent UUID cleanups exposed a bug in the parsing code for the
jModulesInfo response, which was passing wrong value for the second
argument to UUID::SetFromStringRef (it passed the length of the string,
whereas the correct value should be the number of decoded bytes we
expect to receive).
This was not picked up by tests, because they test with 16-byte uuids,
for which the function happens to do the right thing even if the length
does not match (if the length does not match, the function does not
update m_num_uuid_bytes member, but that member is already 16 to begin
with).
I fix that and add a test with 20-byte uuid to catch if this regresses.
I have also added more safeguards into the parsing code to fail if we
cannot parse the entire uuid field we recieve. While testing the latter
part, I noticed that the "negative" jModulesInfo tests were succeeding
because we were sending malformed json (and not because the json
contents was invalid), so I make those tests a bit more robuts as well.
llvm-svn: 320985
|
|
Summary:
The classes have no dependencies, and they are used both by lldb and
lldb-server, so it makes sense for them to live in the lowest layers.
Reviewers: zturner, jingham
Subscribers: emaste, mgorny, lldb-commits
Differential Revision: https://reviews.llvm.org/D34746
llvm-svn: 306682
|
|
Summary:
It had a dependency on StringConvert and file reading code, which is not
in Utility. I've replaced that code by equivalent llvm operations.
I've added a unit test to demonstrate that parsing a file still works.
Reviewers: zturner, jingham
Subscribers: kubamracek, mgorny, lldb-commits
Differential Revision: https://reviews.llvm.org/D34625
llvm-svn: 306394
|
|
Instead of every test creating a client-server combo, do that in the
SetUp method of the test fixture. This also means that we can rely on
gtest to not run the test if the SetUp method fails and delete the
if(HasFailure) calls.
llvm-svn: 306013
|
