| Age | Commit message (Collapse) | Author | Files | Lines |
|---|
|
Currently, when specifying `vectorize(disable) unroll_count(8)`, the
generated metadata appears as follows:
```
!loop0 = !{!"loop0", !vectorize_width, !followup}
!vectorize_width = !{!"llvm.loop.vectorize.width", i32 1}
!followup = !{!"llvm.loop.vectorize.followup_all", !unroll}
!unroll = !{!"llvm.loop.unroll_count", i32 8}
```
Since the metadata `!vectorize_width` implies that the vectorization is
disabled, the vectorization process is skipped, and the `!followup`
metadata is not processed correctly.
This patch addresses the issue by directly appending properties to the
metadata node when vectorization is disabled, instead of creating a new
follow-up MDNode. In the above case, the generated metadata will now
look like this:
```
!loop0 = !{!"loop0", !vectorize_width, !vectorize_width, !unroll}
!vectorize_width = !{!"llvm.loop.vectorize.width", i32 1}
!unroll = !{!"llvm.loop.unroll_count", i32 8}
```
|
|
|
|
(#131985)
When pragma of loop transformations is specified, follow-up metadata for
loops is generated after each transformation. On the LLVM side,
follow-up metadata is expected to be a list of properties, such as the
following:
```
!followup = !{!"llvm.loop.vectorize.followup_all", !mp, !isvectorized}
!mp = !{!"llvm.loop.mustprogress"}
!isvectorized = !{"llvm.loop.isvectorized"}
```
However, on the clang side, the generated metadata contains an MDNode
that has those properties, as shown below:
```
!followup = !{!"llvm.loop.vectorize.followup_all", !loop_id}
!loop_id = distinct !{!loop_id, !mp, !isvectorized}
!mp = !{!"llvm.loop.mustprogress"}
!isvectorized = !{"llvm.loop.isvectorized"}
```
According to the
[LangRef](https://llvm.org/docs/TransformMetadata.html#transformation-metadata-structure),
the LLVM side is correct. Due to this inconsistency, follow-up metadata
was not interpreted correctly, e.g., only one transformation is applied
when multiple pragmas are used.
This patch fixes clang side to emit followup metadata in correct format.
|
|
This patch allows using `getSpecificAttr` for getting `const`
attributes. Previously, if users of this API would want to get a const
Attribute pointer, they had to pass `getSpecificAttr<const XYZ>()`, to
get it compile. It feels like an arbitrary limitation as the constness
was already encoded in the Attribute container's value type.
|
|
Follow up to #109133.
|
|
spec: https://github.com/microsoft/hlsl-specs/pull/263
- `Attr.td` - Define the HLSL loop attribute hints (unroll and loop)
- `AttrDocs.td` - Add documentation for unroll and loop
- `CGLoopInfo.cpp` - Add codegen for HLSL unroll that maps to clang
unroll expectations
- `ParseStmt.cpp` - For statements if HLSL define DeclSpecAttrs via
MaybeParseMicrosoftAttributes
- `SemaStmtAttr.cpp` - Add the HLSL loop unroll handeling
resolves #70114
dxc examples:
- for loop: https://hlsl.godbolt.org/z/8EK6Pa139
- while loop: https://hlsl.godbolt.org/z/ebr5MvEcK
- do while: https://hlsl.godbolt.org/z/be8cedoTs
Documentation:
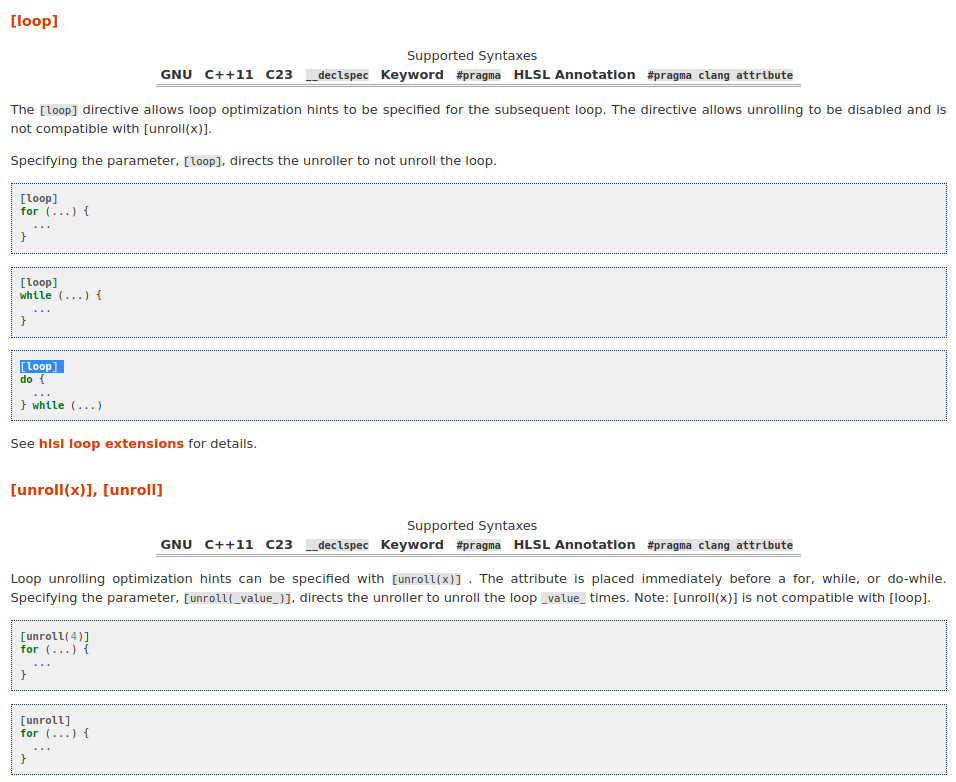
|
|
context (#90240)
PR https://github.com/llvm/llvm-project/pull/89567 fix the `#pragma
unroll N` crash issue in dependent context, but it's introduce an new
issue:
Since https://github.com/llvm/llvm-project/pull/89567, if `N` is value
dependent, 'option' and 'state' were ` (LoopHintAttr::Unroll,
LoopHintAttr::Enable)`. Therefor, clang's code generator generated
incorrect IR metadata.
For the situation `#pragma {GCC} unroll {0|1}`, before template
instantiation, this PR tweak the 'option' to `LoopHintAttr::UnrollCount`
and 'state' to `LoopHintAttr::Numeric`. During template instantiation
and if unroll count is 0 or 1 this PR tweak 'option' to
`LoopHintAttr::Unroll` and 'state' to `LoopHintAttr::Disable`. We don't
use `LoopHintAttr::UnrollCount` here because it's will emit an redundant
LLVM IR metadata `!{!"llvm.loop.unroll.count", i32 1}` when unroll count
is 1.
---------
Signed-off-by: yronglin <yronglin777@gmail.com>
|
|
and `#pragma unroll` (#88666)
Fixes https://github.com/llvm/llvm-project/issues/88624
GCC allows the value of loop unroll count to be zero, and the values of
0 and 1 block any unrolling of the loop. This PR aims to make clang
keeps the same behavior with GCC.
https://gcc.gnu.org/onlinedocs/gcc/Loop-Specific-Pragmas.html
---------
Signed-off-by: yronglin <yronglin777@gmail.com>
|
|
This patch adds support for new loop attribute:
[[clang::code_align(N)]].
This attribute applies to a loop and specifies the byte alignment for a
loop.
The attribute accepts a positive integer constant initialization
expression
indicating the number of bytes for the minimum alignment boundary.
Its value must be a power of 2, between 1 and 4096 (inclusive).
|
|
This patch replaces (llvm::|)Optional< with std::optional<. I'll post
a separate patch to remove #include "llvm/ADT/Optional.h".
This is part of an effort to migrate from llvm::Optional to
std::optional:
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
|
|
This patch adds #include <optional> to those files containing
llvm::Optional<...> or Optional<...>.
I'll post a separate patch to actually replace llvm::Optional with
std::optional.
This is part of an effort to migrate from llvm::Optional to
std::optional:
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
|
|
This patch mechanically replaces None with std::nullopt where the
compiler would warn if None were deprecated. The intent is to reduce
the amount of manual work required in migrating from Optional to
std::optional.
This is part of an effort to migrate from llvm::Optional to
std::optional:
https://discourse.llvm.org/t/deprecating-llvm-optional-x-hasvalue-getvalue-getvalueor/63716
|
|
pragma is specified.
This patch ensures that vector predication and vectorization width
pragmas work together correctly/as expected. Specifically, this patch
fixes the issue that when vectorization_width > 1, the vector
predication behaviour (this would matter if it has NOT been disabled
explicitly by a pragma) was getting ignored, which was incorrect.
The fix here removes the dependence of vector predication on the
vectorization width. The loop metadata corresponding to clang loop
pragma vectorize_predicate is always emitted, if the pragma is
specified, even if vectorization is disabled by vectorize_width(1)
or vectorize(disable) since the option is also used for interleaving
by the LoopVectorize pass.
Reviewed By: dmgreen, Meinersbur
Differential Revision: https://reviews.llvm.org/D94779
|
|
This patch adds support for two new variants of the vectorize_width
pragma:
1. vectorize_width(X[, fixed|scalable]) where an optional second
parameter is passed to the vectorize_width pragma, which indicates if
the user wishes to use fixed width or scalable vectorization. For
example the user can now write something like:
#pragma clang loop vectorize_width(4, fixed)
or
#pragma clang loop vectorize_width(4, scalable)
In the absence of a second parameter it is assumed the user wants
fixed width vectorization, in order to maintain compatibility with
existing code.
2. vectorize_width(fixed|scalable) where the width is left unspecified,
but the user hints what type of vectorization they prefer, either
fixed width or scalable.
I have implemented this by making use of the LLVM loop hint attribute:
llvm.loop.vectorize.scalable.enable
Tests were added to
clang/test/CodeGenCXX/pragma-loop.cpp
for both the 'fixed' and 'scalable' optional parameter.
See this thread for context: http://lists.llvm.org/pipermail/cfe-dev/2020-November/067262.html
Differential Revision: https://reviews.llvm.org/D89031
|
|
Since C++11, the C++ standard has a forward progress guarantee
[intro.progress], so all such functions must have the `mustprogress`
requirement. In addition, from C11 and onwards, loops without a non-zero
constant conditional or no conditional are also required to make
progress (C11 6.8.5p6). This patch implements these attribute deductions
so they can be used by the optimization passes.
Differential Revision: https://reviews.llvm.org/D86841
|
|
This is a long-delayed follow-up to
5e5b85098dbeaea2cfa5d01695b5d2982634d7dd.
`TempMDNode` includes a bunch of machinery for RAUW, and should only be
used when necessary. RAUW wasn't being used in any of these cases... it
was just a placeholder for a self-reference.
Where the real node was using `MDNode::getDistinct`, just replace the
temporary argument with `nullptr`.
Where the real node was using `MDNode::get`, the `replaceOperandWith`
call was "promoting" the node to a distinct one implicitly due to
self-reference detection in `MDNode::handleChangedOperand`. The
`TempMDNode` was serving a purpose by delaying uniquing, but it's way
simpler to just call `MDNode::getDistinct` in the first place.
Note that using a self-reference at all in these places is a hold-over
from before `distinct` metadata existed. It was an old trick to create
distinct nodes. It would be intrusive to change, including bitcode
upgrades, etc., and it's harmless so I'm not sure there's much value in
removing it from existing schemas. After this commit it still has a tiny
memory cost (in the extra metadata operand) but no more overhead in
construction.
Differential Revision: https://reviews.llvm.org/D90079
|
|
Currently Clang does not respect -fno-unroll-loops during LTO. During
D76916 it was suggested to respect -fno-unroll-loops on a TU basis.
This patch uses the existing llvm.loop.unroll.disable metadata to
disable loop unrolling explicitly for each loop in the TU if
unrolling is disabled. This should ensure that loops from TUs compiled
with -fno-unroll-loops are skipped by the unroller during LTO.
This also means that if a loop from a TU with -fno-unroll-loops
gets inlined into a TU without this option, the loop won't be
unrolled.
Due to the fact that some transforms might drop loop metadata, there
potentially are cases in which we still unroll loops from TUs with
-fno-unroll-loops. I think we should fix those issues rather than
introducing a function attribute to disable loop unrolling during LTO.
Improving the metadata handling will benefit other use cases, like
various loop pragmas, too. And it is an improvement to clang completely
ignoring -fno-unroll-loops during LTO.
If that direction looks good, we can use a similar approach to also
respect -fno-vectorize during LTO, at least for LoopVectorize.
In the future, this might also allow us to remove the UnrollLoops option
LLVM's PassManagerBuilder.
Reviewers: Meinersbur, hfinkel, dexonsmith, tejohnson
Reviewed By: Meinersbur, tejohnson
Differential Revision: https://reviews.llvm.org/D77058
|
|
This has very little impact on build time, but is a mechanical pre-req
to removing the OpenMPClause.h include, which matters. Most of these
pretty print methods require Expr to be complete.
|
|
Let's try this again; this has been reverted/recommited a few times. Last time
this got reverted because for this loop:
void a() {
#pragma clang loop vectorize(disable)
for (;;)
;
}
vectorisation was incorrectly enabled and the vectorize.enable metadata was set
due to a logic error. But with this fixed, we now imply vectorisation when:
1) vectorisation is enabled, which means: VectorizeWidth > 1,
2) and don't want to add it when it is disabled or enabled, otherwise we would
be incorrectly setting it or duplicating the metadata, respectively.
This should fix PR27643.
Differential Revision: https://reviews.llvm.org/D69628
|
|
This reverts commit 80371c74ae63d2f260bcc75408be9c6f81e38465.
Given the following source:
```
void a() {
for (;;)
;
}
```
It incorrectly enables vectorization (with vector width 1), as well as generating a warning that vectorization could not be performed.
|
|
This was further discussed at the llvm dev list:
http://lists.llvm.org/pipermail/llvm-dev/2019-October/135602.html
I think the brief summary of that is that this change is an improvement,
this is the behaviour that we expect and promise in ours docs, and also
as a result there are cases where we now emit diagnostics whereas before
pragmas were silently ignored. Two areas where we can improve: 1) the
diagnostic message itself, and 2) and in some cases (e.g. -Os and -Oz)
the vectoriser is (quite understandably) not triggering.
Original commit message:
Specifying the vectorization width was supposed to implicitly enable
vectorization, except that it wasn't really doing this. It was only
setting the vectorize.width metadata, but not vectorize.enable.
This should fix PR27643.
llvm-svn: 374288
|
|
This broke the Chromium build. Consider the following code:
float ScaleSumSamples_C(const float* src, float* dst, float scale, int width) {
float fsum = 0.f;
int i;
#if defined(__clang__)
#pragma clang loop vectorize_width(4)
#endif
for (i = 0; i < width; ++i) {
float v = *src++;
fsum += v * v;
*dst++ = v * scale;
}
return fsum;
}
Compiling at -Oz, Clang now warns:
$ clang++ -target x86_64 -Oz -c /tmp/a.cc
/tmp/a.cc:1:7: warning: loop not vectorized: the optimizer was unable to
perform the requested transformation; the transformation might be disabled or
specified as part of an unsupported transformation ordering
[-Wpass-failed=transform-warning]
this suggests it's not actually enabling vectorization hard enough.
At -Os it asserts instead:
$ build.release/bin/clang++ -target x86_64 -Os -c /tmp/a.cc
clang-10: /work/llvm.monorepo/llvm/lib/Transforms/Vectorize/LoopVectorize.cpp:2734: void
llvm::InnerLoopVectorizer::emitMemRuntimeChecks(llvm::Loop*, llvm::BasicBlock*): Assertion `
!BB->getParent()->hasOptSize() && "Cannot emit memory checks when optimizing for size"' failed.
Of course neither of these are what the developer expected from the pragma.
> Specifying the vectorization width was supposed to implicitly enable
> vectorization, except that it wasn't really doing this. It was only
> setting the vectorize.width metadata, but not vectorize.enable.
>
> This should fix PR27643.
>
> Differential Revision: https://reviews.llvm.org/D66290
llvm-svn: 372225
|
|
Specifying the vectorization width was supposed to implicitly enable
vectorization, except that it wasn't really doing this. It was only
setting the vectorize.width metadata, but not vectorize.enable.
This should fix PR27643.
Differential Revision: https://reviews.llvm.org/D66290
llvm-svn: 372082
|
|
CGLoopInfo was keeping pointers to parent loop LoopInfos, but when the loop info vector grew, it reallocated the storage and invalidated all of the parent pointers, causing use-after-free. Manage the lifetimes of the LoopInfos separately so that the pointers aren't stale.
Patch by Bevin Hansson.
llvm-svn: 369259
|
|
New pragma "vectorize_predicate(enable)" now implies "vectorize(enable)",
and it is ignored when vectorization is disabled with e.g.
"vectorize(disable) vectorize_predicate(enable)".
Differential Revision: https://reviews.llvm.org/D65776
llvm-svn: 368970
|
|
This adds a new vectorize predication loop hint:
#pragma clang loop vectorize_predicate(enable)
that can be used to indicate to the vectoriser that all (load/store)
instructions should be predicated (masked). This allows, for example, folding
of the remainder loop into the main loop.
This patch will be followed up with D64916 and D65197. The former is a
refactoring in the loopvectorizer and the groundwork to make tail loop folding
a more general concept, and in the latter the actual tail loop folding
transformation will be implemented.
Differential Revision: https://reviews.llvm.org/D64744
llvm-svn: 366989
|
|
transformation.
Before this patch, CGLoop would dump all transformations for a loop into
a single LoopID without encoding any order in which to apply them.
rL348944 added the possibility to encode a transformation order using
followup-attributes.
When a loop has more than one transformation, use the follow-up
attribute define the order in which they are applied. The emitted order
is the defacto order as defined by the current LLVM pass pipeline,
which is:
LoopFullUnrollPass
LoopDistributePass
LoopVectorizePass
LoopUnrollAndJamPass
LoopUnrollPass
MachinePipeliner
This patch should therefore not change the assembly output, assuming
that all explicit transformations can be applied, and no implicit
transformations in-between. In the former case,
WarnMissedTransformationsPass should emit a warning (except for
MachinePipeliner which is not implemented yet). The latter could be
avoided by adding 'llvm.loop.disable_nonforced' attributes.
Because LoopUnrollAndJamPass processes a loop nest, generation of the
MDNode is delayed to after the inner loop metadata have been processed.
A temporary LoopID is therefore used to annotate instructions and
RAUW'ed by the actual LoopID later.
Differential Revision: https://reviews.llvm.org/D57978
llvm-svn: 357415
|
|
__attribute__((opencl_unroll_hint))
Summary:
[OpenCL] Generate 'unroll.enable' metadata for __attribute__((opencl_unroll_hint))
For both !{!"llvm.loop.unroll.enable"} and !{!"llvm.loop.unroll.full"} the unroller
will try to fully unroll a loop unless the trip count is not known at compile time.
In that case for '.full' metadata no unrolling will be processed, while for '.enable'
the loop will be partially unrolled with a heuristically chosen unroll factor.
See: docs/LanguageExtensions.rst
From https://www.khronos.org/registry/OpenCL/sdk/2.0/docs/man/xhtml/attributes-loopUnroll.html
__attribute__((opencl_unroll_hint))
for (int i=0; i<2; i++)
{
...
}
In the example above, the compiler will determine how much to unroll the loop.
Before the patch for __attribute__((opencl_unroll_hint)) was generated metadata
!{!"llvm.loop.unroll.full"}, which limits ability of loop unroller to decide, how
much to unroll the loop.
Reviewers: Anastasia, yaxunl
Reviewed By: Anastasia
Subscribers: zzheng, dmgreen, jdoerfert, cfe-commits, asavonic, AlexeySotkin
Tags: #clang
Differential Revision: https://reviews.llvm.org/D59493
llvm-svn: 356571
|
|
to reflect the new license.
We understand that people may be surprised that we're moving the header
entirely to discuss the new license. We checked this carefully with the
Foundation's lawyer and we believe this is the correct approach.
Essentially, all code in the project is now made available by the LLVM
project under our new license, so you will see that the license headers
include that license only. Some of our contributors have contributed
code under our old license, and accordingly, we have retained a copy of
our old license notice in the top-level files in each project and
repository.
llvm-svn: 351636
|
|
This patch adds #pragma clang loop pipeline and #pragma clang loop pipeline_initiation_interval for debugging or reducing compile time purposes. It is possible to disable SWP for concrete loops to save compilation time or to find bugs by not doing SWP to certain loops. It is possible to set value of initiation interval to concrete number to save compilation time by not doing extra pipeliner passes or to check created schedule for specific initiation interval.
Patch by Alexey Lapshin.
llvm-svn: 350414
|
|
llvm.mem.parallel_loop_access metadata.
Instead of generating llvm.mem.parallel_loop_access metadata, generate
llvm.access.group on instructions and llvm.loop.parallel_accesses on
loops. There is one access group per generated loop.
This is clang part of D52116/r349725.
Differential Revision: https://reviews.llvm.org/D52117
llvm-svn: 349823
|
|
struct LoopHint was only used within Parse and not in any of the Sema or
Codegen files. In the non-Parse files where it was included, it either wasn't
used or LoopHintAttr was used, so its inclusion did nothing.
llvm-svn: 347728
|
|
and use the range based successor API.
llvm-svn: 344730
|
|
Summary:
Emit !llvm.mem.parallel_loop_access metadata for memory accesses even if the parallel loop is not the top on the loop stack.
Fixes llvm.org/PR37558.
Reviewers: ABataev, hfinkel, amusman, tyler.nowicki
Reviewed By: hfinkel
Subscribers: Meinersbur, hfinkel, cfe-commits
Differential Revision: https://reviews.llvm.org/D48808
llvm-svn: 338810
|
|
This adds support for the unroll_and_jam pragma, to go with the recently
added unroll and jam pass. The name of the pragma is the same as is used
in the Intel compiler, and most of the code works the same as for unroll.
#pragma clang loop unroll_and_jam has been separated into a different
patch. This part adds #pragma unroll_and_jam with an optional count, and
#pragma no_unroll_and_jam to disable the transform.
Differential Revision: https://reviews.llvm.org/D47267
llvm-svn: 338566
|
|
sed -Ei 's/[[:space:]]+$//' include/**/*.{def,h,td} lib/**/*.{cpp,h}
llvm-svn: 338291
|
|
No functionality change. Found by clang-tidy's
performance-unnecessary-value-param.
llvm-svn: 287894
|
|
can be used to improve the locations when generating remarks for loops.
Depends on the companion LLVM change r286227.
Patch by Florian Hahn.
Differential Revision: https://reviews.llvm.org/D25764
llvm-svn: 286456
|
|
llvm-svn: 279608
|
|
Summary:
This is similar to other loop pragmas like 'vectorize'. Currently it
only has state values: distribute(enable) and distribute(disable). When
one of these is specified the corresponding loop metadata is generated:
!{!"llvm.loop.distribute.enable", i1 true/false}
As a result, loop distribution will be attempted on the loop even if
Loop Distribution in not enabled globally. Analogously, with 'disable'
distribution can be turned off for an individual loop even when the pass
is otherwise enabled.
There are some slight differences compared to the existing loop pragmas.
1. There is no 'assume_safety' variant which makes its handling slightly
different from 'vectorize'/'interleave'.
2. Unlike the existing loop pragmas, it does not have a corresponding
numeric pragma like 'vectorize' -> 'vectorize_width'. So for the
consistency checks in CheckForIncompatibleAttributes we don't need to
check it against other pragmas. We just need to check for duplicates of
the same pragma.
Reviewers: rsmith, dexonsmith, aaron.ballman
Subscribers: bob.wilson, cfe-commits, hfinkel
Differential Revision: http://reviews.llvm.org/D19403
llvm-svn: 272656
|
|
Getting accurate locations for loops is important, because those locations are
used by the frontend to generate optimization remarks. Currently, optimization
remarks for loops often appear on the wrong line, often the first line of the
loop body instead of the loop itself. This is confusing because that line might
itself be another loop, or might be somewhere else completely if the body was
an inlined function call. This happens because of the way we find the loop's
starting location. First, we look for a preheader, and if we find one, and its
terminator has a debug location, then we use that. Otherwise, we look for a
location on an instruction in the loop header.
The fallback heuristic is not bad, but will almost always find the beginning of
the body, and not the loop statement itself. The preheader location search
often fails because there's often not a preheader, and even when there is a
preheader, depending on how it was formed, it sometimes carries the location of
some preceeding code.
I don't see any good theoretical way to fix this problem. On the other hand,
this seems like a straightforward solution: Put the debug location in the
loop's llvm.loop metadata. When emitting debug information, this commit causes
us to add the debug location as an operand to each loop's llvm.loop metadata.
Thus, we now generate this metadata for all loops (not just loops with
optimization hints) when we're otherwise generating debug information.
The remark test case changes depend on the companion LLVM commit r270771.
llvm-svn: 270772
|
|
Besides a small compile-time speedup, there should be no real
functionality change here.
llvm-svn: 264372
|
|
Add support for opencl_unroll_hint attribute from OpenCL v2.0 s6.11.5.
Reusing most of metadata generation from CGLoopInfo helper class.
The code is based on Khronos OpenCL compiler:
https://github.com/KhronosGroup/SPIR/tree/spirv-1.0
Patch by Liu Yaxun (Sam)!
Differential Revision: http://reviews.llvm.org/D16686
llvm-svn: 261350
|
|
This change adds the new unroll metadata "llvm.loop.unroll.enable" which directs
the optimizer to unroll a loop fully if the trip count is known at compile time, and
unroll partially if the trip count is not known at compile time. This differs from
"llvm.loop.unroll.full" which explicitly does not unroll a loop if the trip count is not
known at compile time
With this change "#pragma unroll" generates "llvm.loop.unroll.enable" rather than
"llvm.loop.unroll.full" metadata. This changes the semantics of "#pragma unroll" slightly
to mean "unroll aggressively (fully or partially)" rather than "unroll fully or not at all".
The motivating example for this change was some internal code with a loop marked
with "#pragma unroll" which only sometimes had a compile-time trip count depending
on template magic. When the trip count was a compile-time constant, everything works
as expected and the loop is fully unrolled. However, when the trip count was not a
compile-time constant the "#pragma unroll" explicitly disabled unrolling of the loop(!).
Removing "#pragma unroll" caused the loop to be unrolled partially which was desirable
from a performance perspective.
llvm-svn: 244467
|
|
When ‘#pragma clang loop vectorize(assume_safety)’ was specified on a loop other loop hints were lost. The problem is that CGLoopInfo attaches metadata differently than EmitCondBrHints in CGStmt. For do-loops CGLoopInfo attaches metadata to the br in the body block and for while and for loops, the inc block. EmitCondBrHints on the other hand always attaches data to the br in the cond block. When specifying assume_safety CGLoopInfo emits an empty llvm.loop metadata shadowing the metadata in the cond block. Loop transformations like rotate and unswitch would then eliminate the cond block and its non-empty metadata.
This patch unifies both approaches for adding metadata and modifies the existing safety tests to include non-assume_safety loop hints.
llvm-svn: 243315
|
|
Rename Vectorizer to Vectorize and VectorizeUnroll to InterleaveCount.
llvm-svn: 242241
|
|
llvm-svn: 239576
|
|
Specifying #pragma clang loop vectorize(assume_safety) on a loop adds the
mem.parallel_loop_access metadata to each load/store operation in the loop. This
metadata tells loop access analysis (LAA) to skip memory dependency checking.
llvm-svn: 239572
|
|
llvm-svn: 239365
|
|
`MDNode::getTemporary()` returns a `unique_ptr<>` as of r226504.
llvm-svn: 226505
|
